데이터가 많아져 애플리케이션 속도에 영향을 끼치기 시작하면 샤딩을 고민합니다.
또는 데이터가 없더라도 분산 데이터 스토리지를 선택하곤 합니다.
하지만 수십억 개의 데이터가 있는 테이블이 있고,
이 테이블을 사용하는 유즈케이스가 단일 머신에 적합하다면 샤딩해야할 필요가 없습니다.
왜냐하면 샤딩은 무한한 확장이라는 장점이 있긴 하지만 운영 복잡성이 올라가고, 애플리케이션의 책임이 늘어나는 등 꽤 비싼 비용이 들기 때문입니다.
샤딩을 선택하기 전에 다음과 같은 해결책을 고민해봐야 합니다.
1. Scale Up
수직적 확장이라고 표현하는 스케일업은 머신의 리소스 자체를 업그레이드 하는 것입니다.
언젠가 하드웨어의 업그레이드 또한 한계에 도달할 수 있으나 그때까지는 애플리케이션과 데이터베이스의 아키텍처를 재설계 할 필요가 없는 옵션입니다.
2. Read Scaling
만약 해당 데이터로 수행하는 연산의 대부분이 읽기라면 읽기와 쓰기를 분리할 수 있습니다.
Replication을 좀 더 만들어서 읽기를 분산하고 가용성을 높일 수 있습니다.
(원한다면 지리적 위치에 따른 replication 분산으로 조회에 대한 지역성을 높일 수도 있습니다.)
다만 replication이 늘어날수록 leader에 수행되는 write를 모두 복사해야 하므로 write가 많을시 몇가지 고민할 거리들이 생깁니다.
(복제를 동기식,비동기식으로 할건지, 어떤 매커니즘을 사용할지, 복제지연, 최종적 일관성, 동기화, 단조읽기 지원 등, 관련해서는 데이터 중심 애플리케이션 설계 5장 복제 편을 보시면 도움이 됩니다.)
3. 데이터베이스 변경
현재 자신이 사용하고 있는 데이터베이스가 정말 내 애플리케이션 유즈케이스에 맞는 데이터베이스인지 확인이 필요합니다.
방 안의 습도를 1초에 한번씩 수집하여 체크하는 IoT머신을 위한 데이터베이스가 관계형데이터베이스라면 매우 비합리적이라고 볼 수 있습니다.
위와 같은 옵션들이 있고 그럼에도 불구하고 샤딩을 선택해야 한다면, 제가 생각하는 핵심적인 부분은 다음과 같습니다.
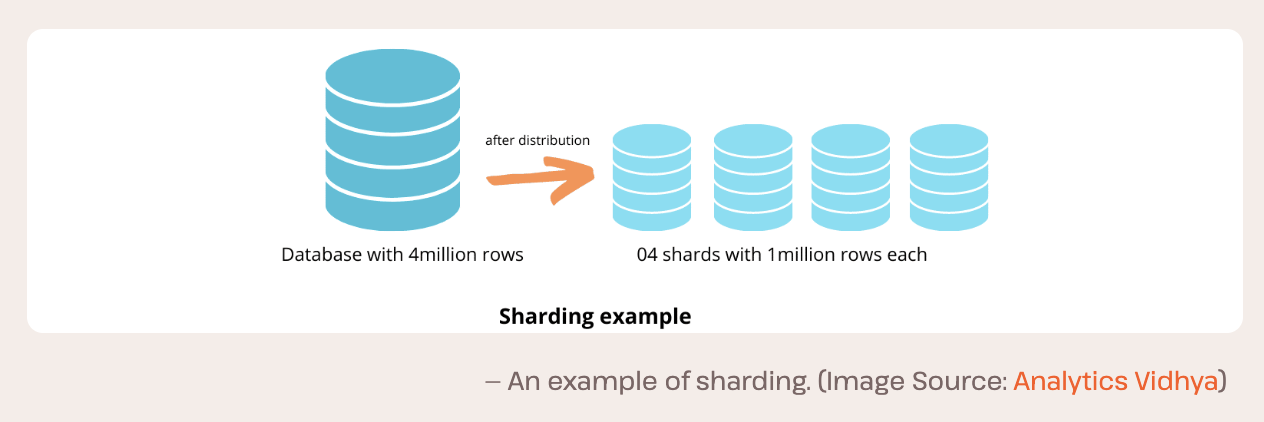
1. 샤드키 설계
샤드키는 데이터가 어떻게 분산되어야 하는지 알려주는 일종의 PK입니다.
동일한 샤드키를 가진 데이터 그룹을 logical shard라고 하고, physical shard라고 하는 데이터베이스 노드에 여러 logical shard가 포함됩니다.
샤드키 설계시 고민해야할 부분은 카디널리티, 데이터 skew(hotspot)방지, 쿼리의 종류 정도 있을 것 같습니다.
단일 노드에 비해 shard의 몸집이 너무 큰 경우에 공간 자체가 부족해지므로 샤드키의 카디널리티를 고민해야 하고,
일부 노드에 데이터가 몰리는 데이터 skew(hotspot 현상)을 방지해야 합니다.
또한 많은 엔티티들이 조합되어야 하는 쿼리가 많다면 지역성을 극대화시켜주는 relationship based 샤딩을 고민해볼 수 있습니다.
이 외에도 앞으로 얼마나 데이터가 많아질 것인지(빠른 시일 내 재샤딩 유무), 일관성 유지의 중요도 등등 고민할 부분이 참 많습니다.
2. 분산 트랜잭션 처리
제일 골치아픈 부분입니다. 키설계를 잘해서 다행히 노드 하나에서 지지고볶고 하더라도 서비스가 성장하면 언젠가 이 분산트랜잭션 문제에 부딪힐 거라고 생각합니다. (저도 맞이하고 있고 아직까지 쉽고 빠른 매우 나이스한 방법을 찾지는 못했습니다.)
결국 우리는 여러 하위 트랜잭션을 orchestration할 수 있는 글로벌 트랜잭션을 만들어야 하고 이는 결국 2PC를 고민하게 합니다.
하지만 2PC는 구현이 복잡하고 결국 leader transaction이 비정상적일 때에 대한 해결법이 없거니와 쓰기 증폭에 대한 애플리케이션 불안정을 야기할 수 있습니다. 이쯤되면 MSA패턴 중 하나인 Saga(코레오그래피, 오케스트레이션 패턴)도 떠오르게 됩니다.
위 이야기들은 해야할 말들이 많아서 다른 챕터에서 다뤄보겠습니다.
(샤드키 설계와 분산트랜잭션 처리 관련해서는 데이터 중심 애플리케이션 설계의 6장, 7장을 참고해보시기 바랍니다.)
지금까지 분산 스토리지를 고민할때, 혹은 데이터가 많아져서 샤딩을 고민할 때 과연 다른 해결법은 없는지 알아봤고,
그럼에도 불구하고 샤딩이 필요하다면 어떤 부분을 고민해야 하는지 한번 끄적해봤습니다.
좋은 의견, 다른 의견이 있으면 언제든 댓글 부탁드립니다.
'츄Log > 끄적끄적' 카테고리의 다른 글
| CompletableFuture runAsync/supplyAsync/get (0) | 2024.03.02 |
|---|---|
| CompletableFuture 코드 리뷰 기록 (0) | 2024.02.10 |
| SpringBoot의 Configuration(proxyBeanMethods) (1) | 2024.01.04 |
| Nested Class 종류와 Nested Static Class 사용에 대한 고찰 (2) | 2024.01.04 |
| NoSQL에서 다대일 관계, Join에 대한 지원이 약한 이유 (2) | 2024.01.03 |


