데이터 시스템을 공부하다가 Dense/Sparse feature(data)라는 키워드를 보았습니다.
조금 찾아보니 데이터시스템에서 사용되며 특히 머신러닝에서 많이 사용되는 것 같습니다.
머신러닝 개발자가 아니므로 가볍게 키워드만 알아보려고 합니다.
머신러닝에서 feature는 특정 가능하고 수량화 가능한 속성이나 사물, 사람 또는 현상의 "특성"을 나타내는 말입니다.
이 feature는 크게 dense와 sparse로 분류할 수 있습니다.
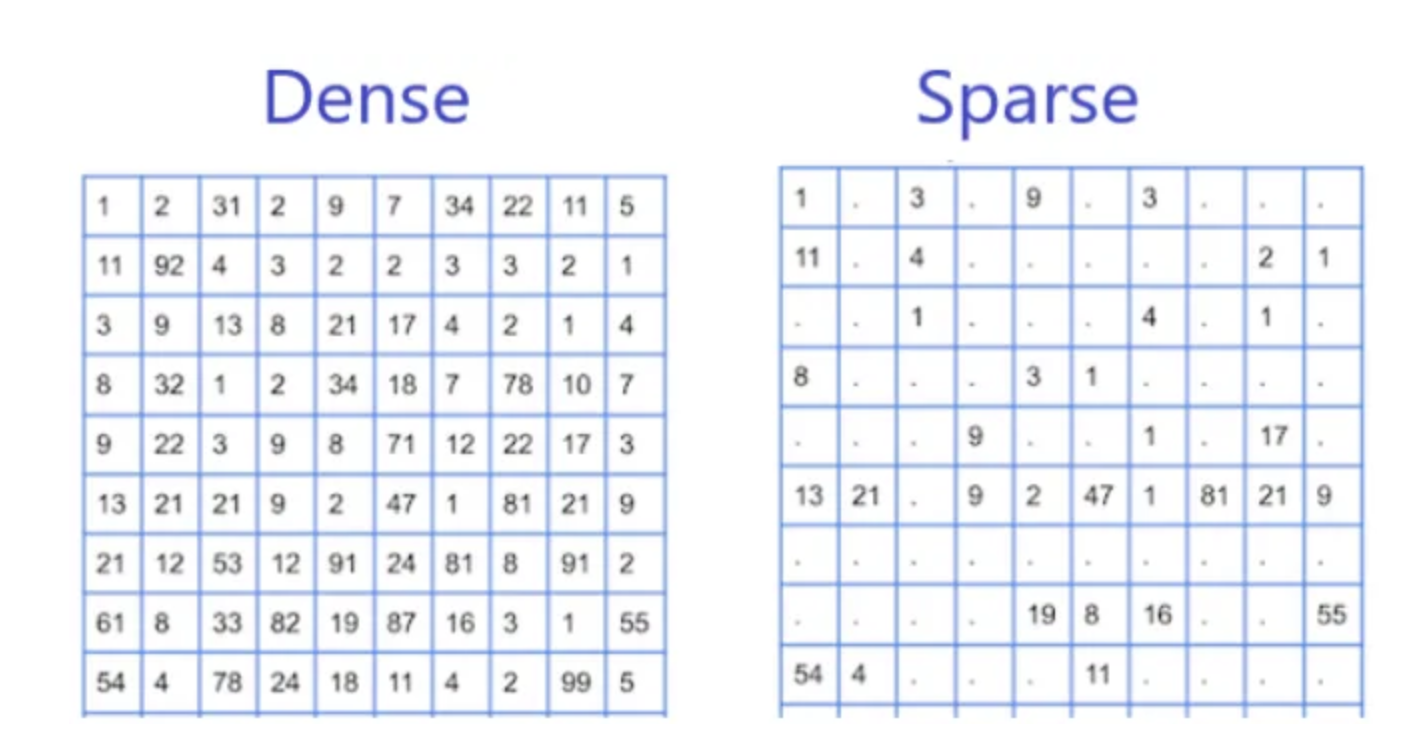
Dense는 말 그대로 밀집된 데이터이며 Sparse는 희소한 데이터입니다.
분포의 정도에 따라 machine learning 알고리즘에 영향을 미칩니다.
알고리즘은 dense/sparse 특징에 따라 다르게 수행될 수 있기 때문입니다.
1. Dense
데이터 세트에서 자주 혹은 정기적으로 발생하며 대부분의 값이 0이 아닙니다.
데이터 세트에 0이 아닌 값이 많기 때문에 dense 라고 하며, 종류에는 인구 통계, 연령, 성별, 소득등이 있습니다.
일반적으로 데이터가 dense vector로 표현 가능한 이미지나 음석 인식에서 사용됩니다.
2. Sparse
데이터 세트에서 드물거나 산발적으로 발생하는 특성이며 대부분 값은 0이거나 null입니다.
대부분의 값이 0이거나 null이므로 sparse 라고 하며, 종류에는 텍스트 문서에 특정 단어가 있는지, 또는 트랜잭션 데이터세트에 특정 항목이 있는지 등이 있습니다.
희소행렬로 표현되는 자연어처리(NLP) 및 추천시스템에서 일반적입니다.
sparse data는 일반적으로 공간이 크고 0 또는 0에 가까운 값이 많아 계산 비용이 많이 들고 training precess가 느려질 수 있어 작업하기 어려울 수 있습니다. (그래서 데이터시스템으로 확장성 있고 분석에 유리한 NoSQL을 사용하게 됩니다.)
도움 :
https://induraj2020.medium.com/what-are-sparse-features-and-dense-features-8d1746a77035
'츄Log > 데이터 끄적' 카테고리의 다른 글
| 툼스톤(Tombstone)이란? 툼스톤 사용하는 이유 (1) | 2023.12.03 |
|---|
